Comprendere la Tecnologia USB Oltre il Marketing
Analisi continua della memoria flash, della tecnologia USB e della sicurezza dei dati - spiegata chiaramente per coloro che vogliono capire cosa sta realmente accadendo.
Aree Tematiche Principali
Memoria Flash
Come funziona la tecnologia NAND, miti sulla durata, comportamento delle prestazioni e tendenze dei prezzi.
Sicurezza USB
Protezione anticopia, rischi di perdita di dati, protezione da scrittura e realtà di conformità normativa.
Integrità dei Dati
Strumenti di test, unità con falsa capacità, problemi di corruzione e metodi di verifica.
Hardware USB
Cosa c'è dentro una chiavetta flash, comportamento del firmware e compromessi prestazionali.
Sistemi di Duplicazione
Copia in produzione di massa, metodi di verifica e progettazione del flusso di lavoro.
Analisi di Settore
Cambiamenti del mercato, vincoli di fornitura, domanda legata all'IA e dinamiche dei prezzi delle memorie flash.
Analisi In Evidenza
Approfondimenti sui comportamenti USB nel mondo reale, l'economia della memoria flash, le decisioni sui controller e i compromessi sulla sicurezza.
Ultimi Articoli

I computer quantistici sostituiranno l’USB? Perché il computing classico resta fondamentale

M.2 e NVMe sono la stessa cosa? (Spoiler: no)
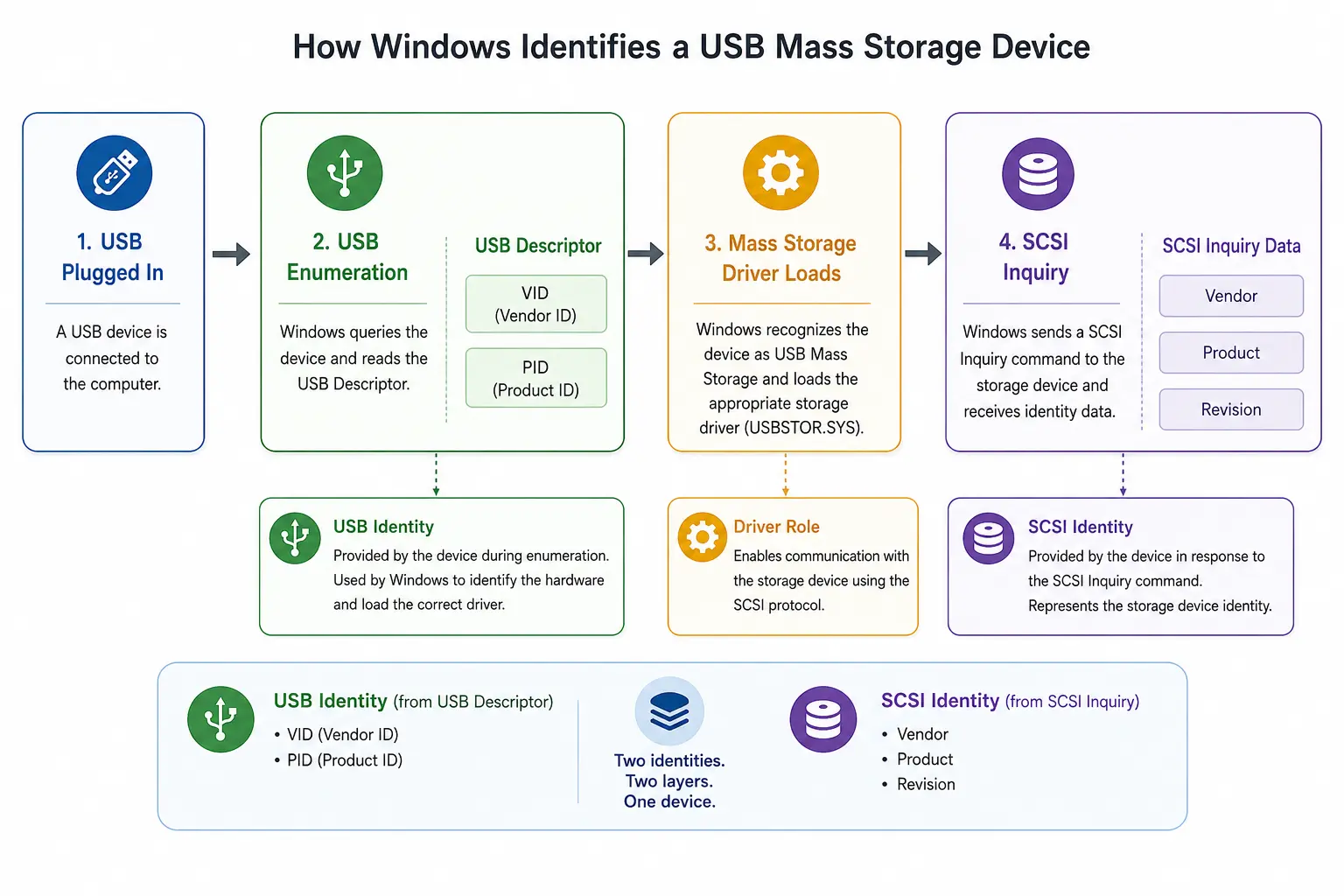
Come trovare VID, PID, produttore SCSI e informazioni sul prodotto di un’unità USB in Windows
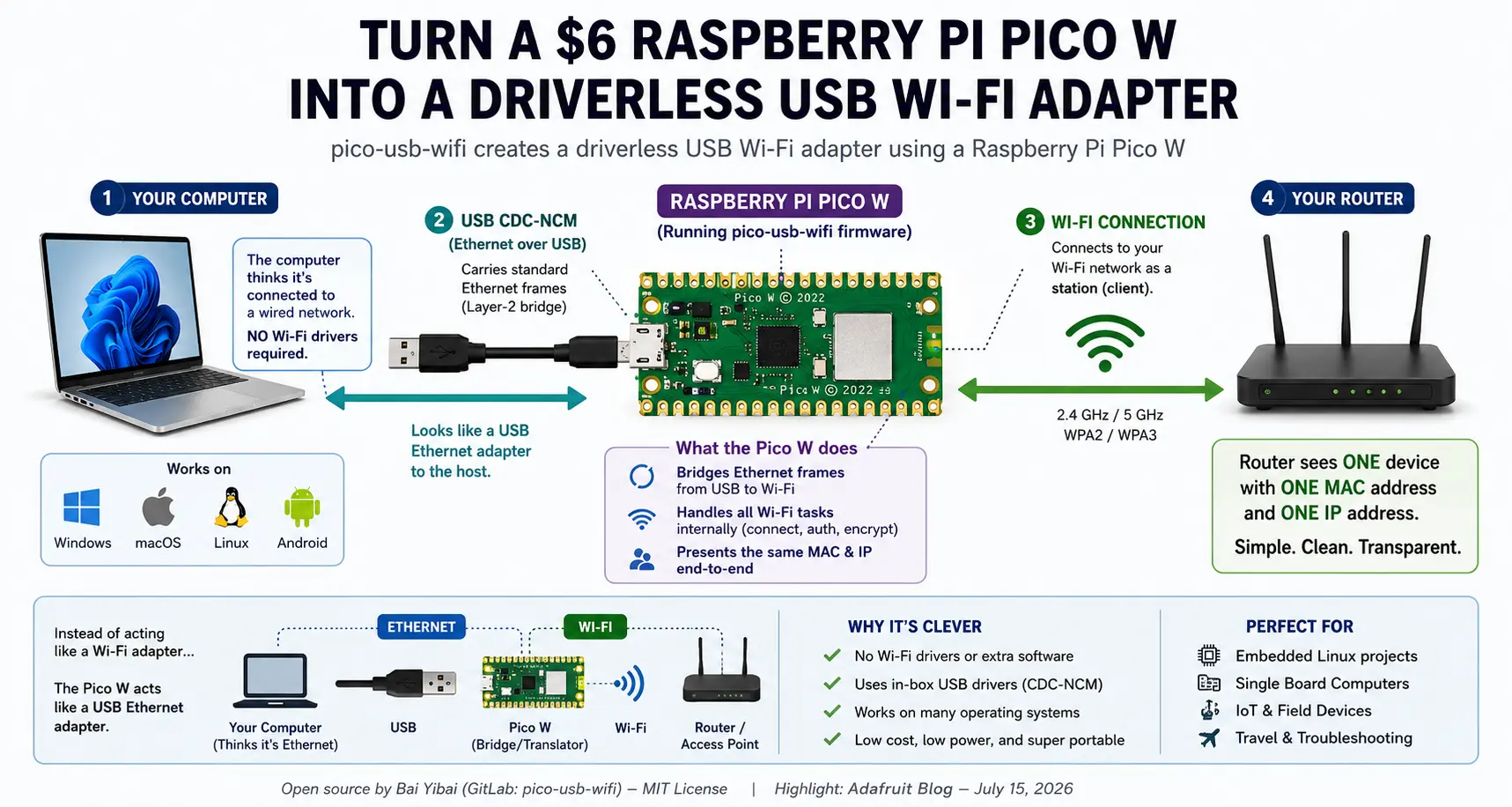
Qualcuno ha trasformato un Raspberry Pi Pico W da 6 dollari in un adattatore Wi-Fi USB senza driver. Ecco perché è un’idea così intelligente
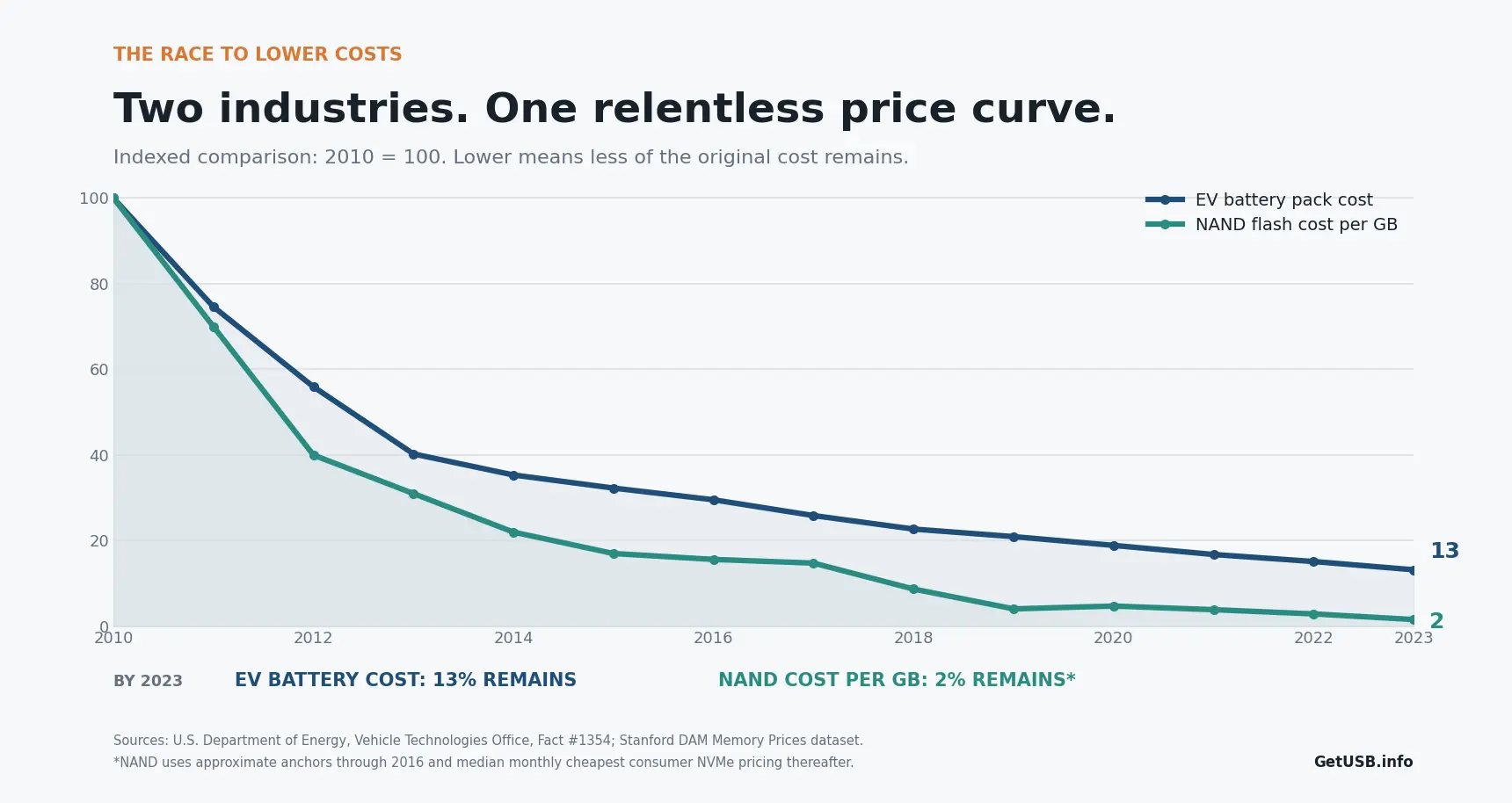
Miliardi per costruire. Centesimi per unità
