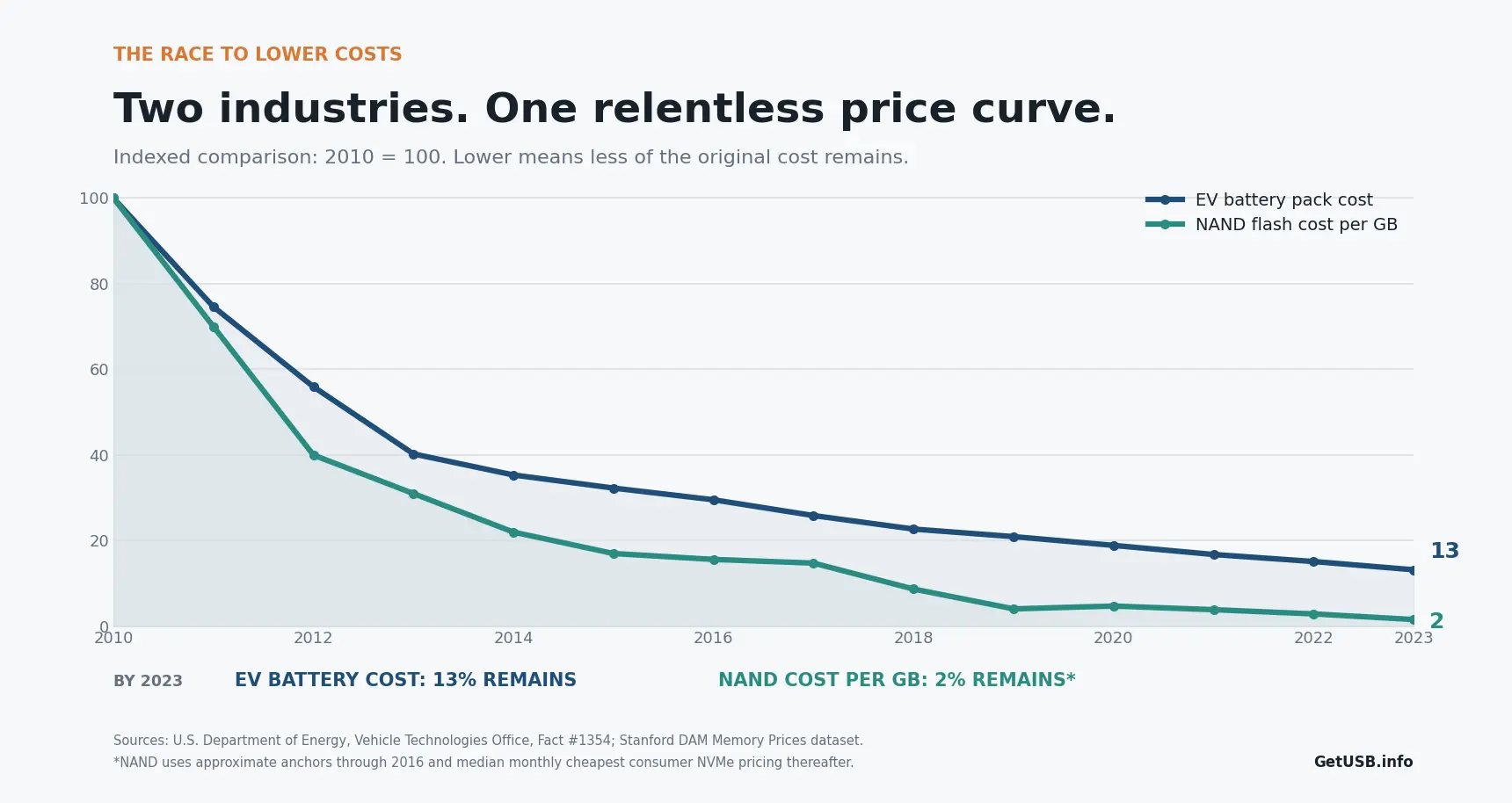
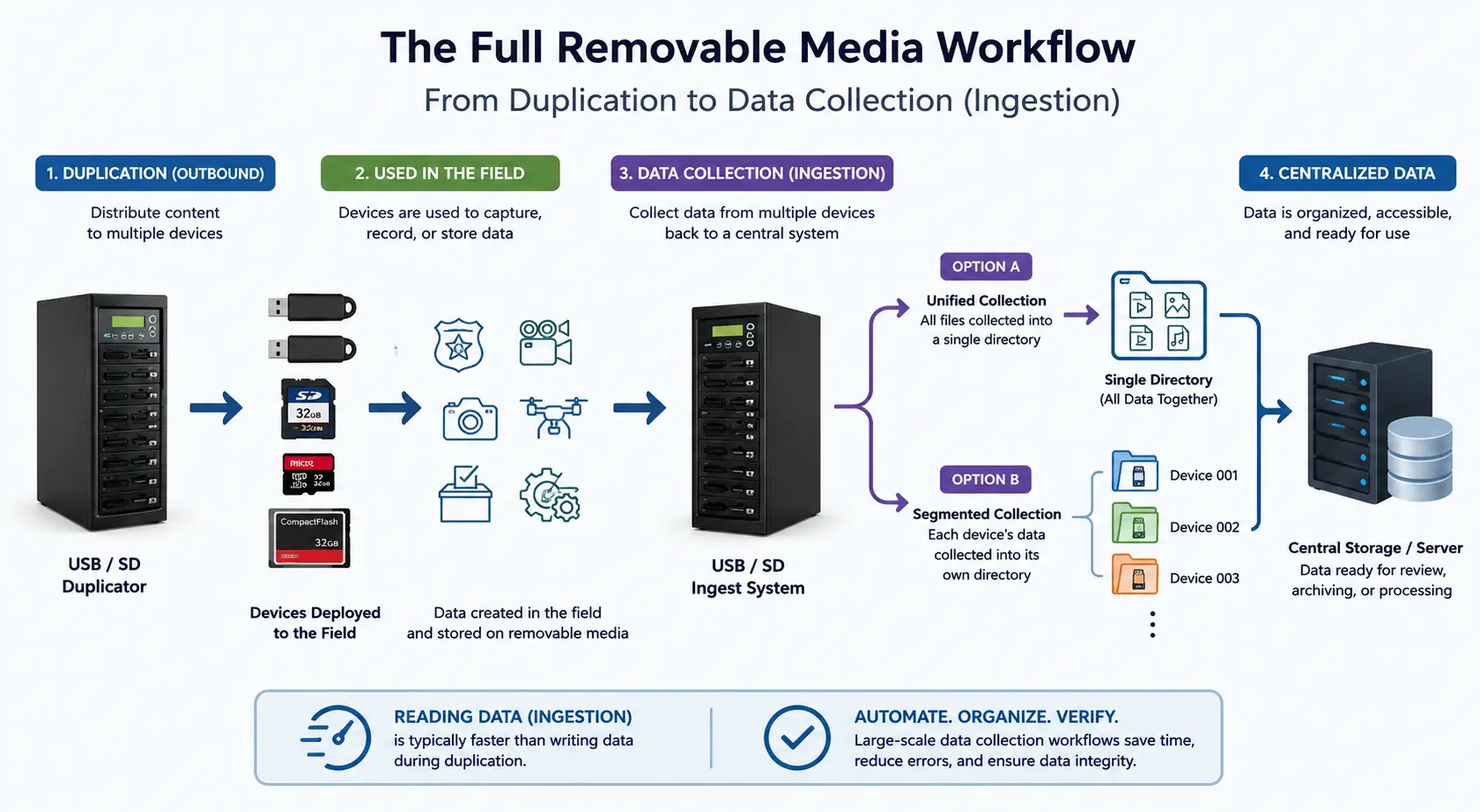
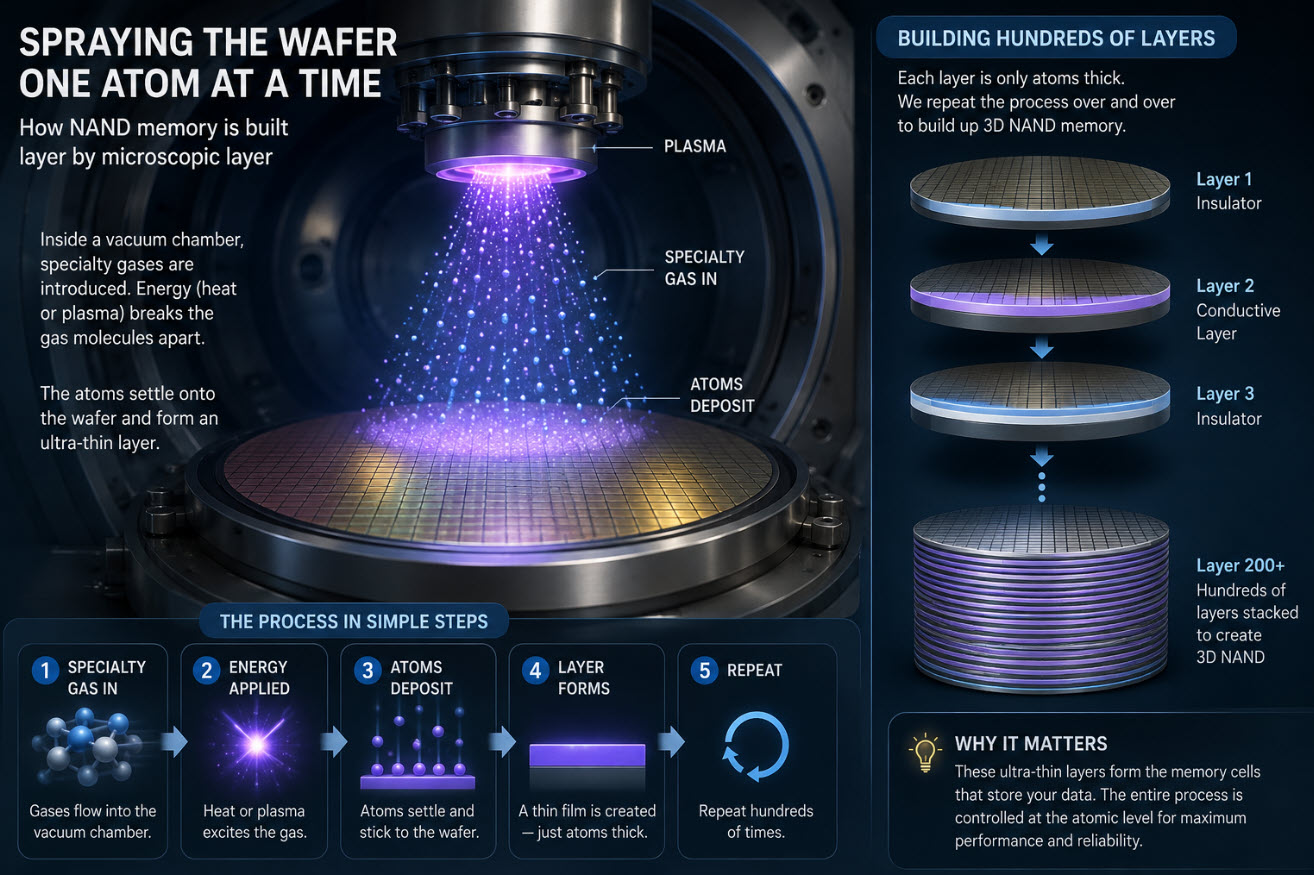
Perché è così difficile credere che una chiavetta USB possa scrivere a 400MB/sec – e restare comunque precisa