
Perché l’AI sta spostando il calcolo più vicino allo storage
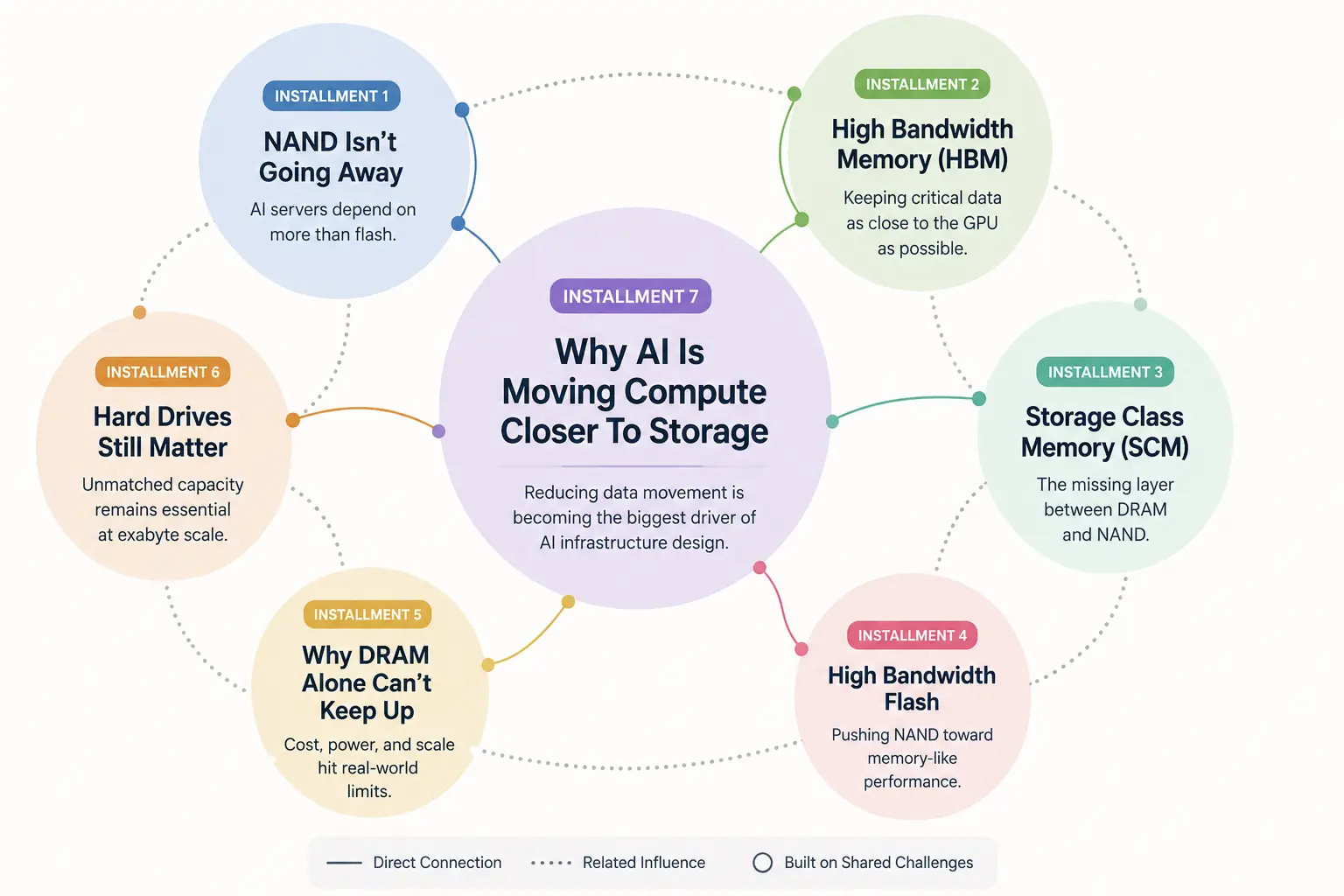
Se hai seguito i precedenti articoli di questa serie, probabilmente avrai iniziato a notare uno schema che sta emergendo.
Nel primo articolo abbiamo spiegato come la memoria flash NAND non stia scomparendo, ma stia invece diventando parte di una gerarchia di memoria AI molto più ampia. Poi abbiamo parlato della High Bandwidth Memory (HBM) e del motivo per cui le GPU moderne dipendono dall’avere i dati fisicamente più vicini al processore. Da lì siamo passati alla Storage Class Memory, alla High Bandwidth Flash, ai limiti della scalabilità della DRAM e infine al motivo per cui anche gli hard disk tradizionali restano ancora fondamentali, perché l’infrastruttura AI opera su una scala che la maggior parte delle persone sottovaluta parecchio.
A prima vista, questi possono sembrare argomenti separati.
Non lo sono.
Sono tutti sintomi della stessa pressione di fondo: i sistemi AI non stanno più lottando principalmente con la potenza di calcolo. Stanno lottando con l’efficienza con cui riescono a spostare i dati.
Questo cambiamento modifica quasi tutto nel modo in cui viene progettata l’infrastruttura.
Per decenni, l’informatica ha seguito un modello abbastanza stabile. Lo storage conservava i dati, la memoria li preparava temporaneamente e i processori recuperavano ciò di cui avevano bisogno. Man mano che i processori diventavano più veloci, il sistema cercava semplicemente di alimentarli in modo più efficiente usando bus migliori, cache più grandi e tecnologie di memoria più rapide.
L’AI ha cambiato la scala del problema.
I cluster GPU moderni possono elaborare informazioni a un ritmo così enorme che l’atto stesso di spostare i dati all’interno del sistema ha iniziato a diventare uno dei maggiori colli di bottiglia dell’intera architettura. In alcuni ambienti, il processore in sé non è più la parte lenta. Il ritardo arriva dal portare i dati giusti al processore abbastanza rapidamente e con sufficiente continuità da mantenerlo pienamente utilizzato.
Questa consapevolezza sta spingendo silenziosamente il settore in una nuova direzione.
Invece di continuare a spostare quantità sempre maggiori di dati avanti e indietro nel sistema, l’infrastruttura AI sta iniziando a spostare alcune parti del calcolo più vicino al punto in cui i dati si trovano già.
E una volta capito perché questo sta accadendo, molti degli articoli precedenti di questa serie iniziano a incastrarsi con molta più chiarezza.
L’AI sta iniziando a scontrarsi con il muro dello spostamento dei dati
Una delle idee più importanti dell’articolo precedente sulla HBM era che i sistemi AI moderni spesso rallentano non perché il processore non abbia capacità di calcolo, ma perché il sistema non riesce a fornire dati abbastanza velocemente da tenere occupato il processore.
Questo problema diventa molto più serio quando i carichi di lavoro AI si espandono su interi rack e cluster.
Un moderno acceleratore AI può consumare quantità impressionanti di informazioni in parallelo. Il problema è che i dataset non sono più abbastanza piccoli da stare interamente nei livelli di memoria più veloci. Anche con HBM e grandi pool di DRAM, enormi quantità di dati devono comunque viaggiare attraverso interconnessioni, bus, fabric, livelli di storage e infrastruttura di rete.
Questo movimento ha un costo.
Si manifesta come latenza, ma questa è solo una parte della storia. Si manifesta anche come consumo energetico, calore, richiesta di raffreddamento, congestione, ritardi di sincronizzazione e cicli di calcolo inattivi. Come abbiamo discusso nell’articolo sulla DRAM, anche ritardi minuscoli diventano sorprendentemente costosi quando migliaia di GPU lavorano nello stesso momento. Una piccola pausa moltiplicata su un grande cluster AI può rappresentare un’enorme quantità di utilizzo perso.
Questo cambia le priorità ingegneristiche.
Per anni, l’infrastruttura è stata progettata soprattutto per massimizzare le prestazioni di calcolo. I sistemi AI stanno ora costringendo gli ingegneri a ragionare altrettanto seriamente sulla località dei dati, cioè su dove si trovano fisicamente le informazioni rispetto al processore che deve usarle.
Detto semplicemente, la distanza oggi conta molto più di prima.
Le GPU sono diventate così veloci che il resto del sistema ha iniziato a restare indietro
Una delle cose particolari dell’infrastruttura AI è che il progresso in un’area tende a mettere in evidenza le debolezze da qualche altra parte.
Quando le GPU sono diventate più veloci, la larghezza di banda della memoria è diventata il collo di bottiglia. Questo ha portato alla HBM. Quando i limiti di capacità della HBM sono diventati più evidenti, il settore ha iniziato a introdurre livelli intermedi come la Storage Class Memory. Quando la scalabilità della DRAM è diventata costosa e fisicamente difficile, i sistemi hanno iniziato ad appoggiarsi di più alla NAND, esplorando allo stesso tempo concetti come la High Bandwidth Flash.
E mentre i dataset AI continuavano a espandersi fino all’ordine dei petabyte e degli exabyte, gli hard disk sono rimasti silenziosamente essenziali, perché l’economia necessaria per conservare così tante informazioni semplicemente non poteva funzionare in altro modo.
Ogni articolo di questa serie, in realtà, ha puntato verso la stessa conclusione da un’angolazione diversa.
La vecchia idea secondo cui il calcolo sta qui mentre lo storage sta là sta iniziando a rompersi. Il motivo è piuttosto semplice: le GPU oggi possono elaborare i dati più velocemente di quanto le architetture tradizionali riescano a consegnarli comodamente.
Questo crea una situazione in cui enormi quantità di attività del sistema vengono spese semplicemente per trasportare informazioni da un punto all’altro. In termini pratici, alcuni ambienti AI stanno iniziando ad assomigliare meno a puri problemi di calcolo e più a problemi di logistica.
Il settore ha iniziato a fare una domanda diversa
Per molto tempo, l’innovazione nello storage si è concentrata soprattutto sul rendere i dispositivi di archiviazione più veloci. SSD più veloci, interfacce più rapide, NAND più performante e controller più potenti erano tutti elementi importanti, e lo sono ancora oggi.
Ma i carichi di lavoro AI hanno iniziato a mostrare un problema più profondo sotto tutto questo.
A un certo punto, gli ingegneri hanno iniziato a capire che il problema non era sempre la velocità del dispositivo di storage in sé. Il problema era lo spostamento ripetuto di enormi quantità di dati avanti e indietro attraverso l’intero sistema.
Questa distinzione sottile conta, perché una volta che il problema diventa il movimento dei dati e non la semplice velocità dello storage, anche la soluzione inizia a cambiare.
Invece di chiedersi all’infinito come rendere lo storage più veloce, il settore ha iniziato a chiedersi quanta strada debbano fare i dati in primo luogo.
Questa domanda sta ora influenzando quasi ogni parte della progettazione delle moderne infrastrutture AI.
Spostare il calcolo più vicino a dove i dati si trovano già
È qui che l’architettura comincia a cambiare.
Invece di trattare lo storage come un livello completamente passivo che aspetta semplicemente le richieste, i sistemi più recenti stanno iniziando a svolgere alcune attività più vicino ai dati stessi. Non necessariamente elaborazione GPU completa, ma operazioni localizzate che riducono gli spostamenti inutili nel resto del sistema.
Alcuni sistemi ora eseguono filtraggio, indicizzazione, operazioni di ricerca, compressione, preparazione del recupero e organizzazione dei dati più vicino al livello di storage, prima ancora che le informazioni raggiungano i principali motori di calcolo.
L’obiettivo non è eliminare le GPU o sostituire la memoria veloce. L’obiettivo è ridurre gli sprechi.
Se il sistema può evitare di trasportare enormi quantità di dati non necessari attraverso l’infrastruttura, l’intera piattaforma diventa più efficiente. Questo è uno dei motivi per cui la linea tra calcolo e storage sta iniziando a sfumare.
Lo storage non si comporta più come una destinazione completamente inattiva seduta in fondo alla gerarchia. Sta diventando più coinvolto nel modo in cui i dati vengono preparati, messi in scena, filtrati e consegnati verso i livelli superiori.
Se ripensi all’articolo precedente sulla High Bandwidth Flash, questa direzione ha molto senso. Quell’articolo mostrava come la NAND stessa venisse spinta verso un comportamento più simile alla memoria. Questo articolo estende la stessa idea di un passo ulteriore, mostrando come anche l’architettura circostante si stia adattando al costo dello spostamento dei dati.
L’analogia del magazzino inizia ad assumere un aspetto diverso
L’analogia del magazzino che abbiamo usato in tutta questa serie funziona ancora qui, ma il magazzino stesso ha iniziato a evolversi perché il lavoro al suo interno è cambiato.
Negli articoli precedenti, la disposizione era abbastanza semplice. La HBM rappresentava la banchina di carico dove il pallet successivo era già in attesa accanto agli operatori. La DRAM funzionava come lo spazio operativo attivo dove avvenivano lo smistamento e la gestione immediata. La Storage Class Memory diventava l’area di preparazione appena dietro la banchina, mentre la NAND rappresentava gli scaffali principali del magazzino più indietro. Gli hard disk gestivano lo storage profondo di massa, dove viveva l’inventario a lungo termine, perché la capacità contava più della velocità di accesso immediata.
Quel modello regge ancora in linea generale, ma i sistemi AI stanno iniziando a mostrare inefficienze nella quantità di movimento che avviene tra queste aree.
Immagina un magazzino in cui gli operatori passano più tempo a guidare muletti avanti e indietro per l’edificio che a lavorare effettivamente sull’inventario. All’inizio, la direzione risponde acquistando muletti più veloci, allargando le corsie e migliorando le banchine di carico. Questi aggiornamenti aiutano per un po’, ma alla fine l’operazione arriva a un punto in cui il trasporto stesso diventa il problema. I ritardi non sono più causati da operatori lenti o attrezzature inadeguate. I ritardi derivano dalla pura quantità di movimento necessaria per mantenere attivo il flusso di lavoro.
Questo è sempre più ciò contro cui si stanno scontrando i grandi sistemi AI.
Il problema non è più soltanto quanto velocemente i dati possano essere elaborati una volta arrivati alla GPU. Il problema è quanta fatica infrastrutturale venga spesa per trasportare ripetutamente quei dati attraverso il sistema fin dall’inizio.
Quindi, invece di ottimizzare all’infinito il trasporto, la disposizione comincia a cambiare. Piccole postazioni di lavoro iniziano ad apparire più vicino agli scaffali stessi. Alcune attività di smistamento avvengono localmente. Il filtraggio avviene localmente. La preparazione dei dati comincia ad avvenire più vicino al punto in cui le informazioni si trovano già, riducendo la frequenza con cui il sistema deve spostare enormi quantità di materiale avanti e indietro attraverso l’intera operazione.
Questo cambiamento è essenzialmente ciò che l’infrastruttura AI sta iniziando a fare a livello architetturale. L’obiettivo non è trasformare lo storage in un processore o eliminare del tutto il calcolo centralizzato. L’obiettivo è ridurre il movimento non necessario perché, su scala AI, anche piccole inefficienze diventano sorprendentemente costose quando vengono moltiplicate su migliaia di acceleratori che operano contemporaneamente.
L’infrastruttura AI sta diventando più distribuita per necessità
Una delle conseguenze più interessanti di questo cambiamento è che l’infrastruttura AI sta iniziando a diventare molto più distribuita di quanto gli ambienti di calcolo tradizionali abbiano mai avuto bisogno di essere.
Le architetture più vecchie presumevano che la maggior parte del lavoro importante sarebbe avvenuta in punti di calcolo centralizzati, mentre lo storage sarebbe rimasto in gran parte passivo e separato dal livello di elaborazione. Quel modello ha funzionato ragionevolmente bene per decenni, perché la quantità di dati che si muoveva nel sistema era ancora gestibile rispetto alla velocità dei processori che la consumavano.
L’AI cambia completamente la scala dell’equazione.
La quantità di informazioni che viene elaborata, riesaminata, preparata, memorizzata in cache, indicizzata e recuperata è ormai così grande che il movimento centralizzato stesso inizia a creare inefficienze. Invece di far sì che il calcolo scenda semplicemente verso lo storage ogni volta che ha bisogno di qualcosa, i sistemi stanno cercando sempre più di mantenere i dati utili posizionati più vicino al punto in cui probabilmente verranno usati dopo.
Questo è parte del motivo per cui tecnologie come database vettoriali, sistemi di inferenza distribuita, livelli di recupero, caching localizzato ed elaborazione vicino ai dati hanno iniziato a ricevere tanta attenzione. In superficie, possono sembrare tecnologie separate che risolvono problemi non collegati, ma sotto sotto rispondono tutte alla stessa pressione. Il settore sta cercando di ridurre la frequenza con cui enormi quantità di informazioni devono percorrere lunghe distanze attraverso l’infrastruttura prima che il lavoro significativo possa iniziare.
Come probabilmente hai notato in tutta questa serie, la gerarchia della memoria stessa sta gradualmente diventando meno rigida di quanto fosse una volta. La separazione netta tra “calcolo da questa parte” e “storage da quella parte” sta iniziando ad ammorbidirsi, perché i carichi di lavoro AI premiano i sistemi che mantengono i dati fisicamente più vicini al punto in cui avviene l’elaborazione.
Questa tendenza probabilmente continuerà, perché l’economia dell’AI su larga scala favorisce sempre di più l’efficienza nello spostamento dei dati tanto quanto la capacità di calcolo grezza.
La gerarchia della memoria sta iniziando a confondersi
Uno dei temi più silenziosi che attraversano ogni articolo di questa serie è stata la graduale erosione dei vecchi confini tra memoria, storage e calcolo.
Nell’articolo sulla HBM, abbiamo visto come la memoria sia stata fisicamente spostata più vicino al processore stesso, perché anche il posizionamento tradizionale della DRAM iniziava a introdurre ritardi abbastanza grandi da contare su scala AI. Nell’articolo sulla Storage Class Memory, l’attenzione si è spostata sulla riduzione del salto netto tra memoria veloce e storage persistente più lento. La High Bandwidth Flash ha spinto la NAND verso un ruolo più attivo nel percorso dei dati di lavoro, mentre l’articolo sulla DRAM ha mostrato perché aumentare semplicemente la memoria tradizionale all’infinito diventa difficile sia economicamente sia fisicamente.
Ora questo articolo porta la stessa progressione un passo più avanti, mostrando come l’architettura stessa si stia adattando al costo dello spostamento dei dati.
Ciò che rende la cosa particolarmente interessante è che nessuna di queste tecnologie sta davvero sostituendo le altre. Il settore non ha abbandonato la NAND quando è arrivata la HBM. Non ha sostituito la DRAM semplicemente perché è apparsa la Storage Class Memory. Anche gli hard disk restano profondamente rilevanti, nonostante decenni di previsioni secondo cui lo storage a stato solido li avrebbe eliminati del tutto.
Invece, il sistema sta diventando più stratificato, più specializzato e più consapevole di dove esistano fisicamente i dati rispetto alle risorse di calcolo che cercano di consumarli.
Questa distinzione conta perché cambia il modo in cui dovremmo pensare al futuro dell’infrastruttura AI. L’evoluzione non sta accadendo perché una singola tecnologia rivoluzionaria ha risolto improvvisamente tutto. Sta accadendo perché il carico di lavoro stesso ha costretto il settore a riorganizzare il modo in cui ogni livello partecipa all’alimentazione efficiente delle informazioni verso il lato del calcolo.
Quando fai un passo indietro e guardi il quadro generale, lo schema diventa molto più facile da vedere. Ogni grande cambiamento di cui abbiamo parlato in questa serie punta, in definitiva, allo stesso obiettivo: ridurre quanto tempo, energia e sovraccarico infrastrutturale vengano spesi semplicemente per spostare informazioni da un posto all’altro.
Il futuro potrebbe dipendere più dal posizionamento dei dati che dal calcolo grezzo
Per molto tempo, il settore tecnologico ha misurato il progresso soprattutto attraverso la capacità di calcolo grezza. Processori più veloci, acceleratori più grandi, più core e maggiore parallelismo venivano trattati come i principali indicatori di avanzamento perché, per la maggior parte dei carichi di lavoro tradizionali, migliorare le prestazioni di calcolo migliorava generalmente il sistema nel suo insieme.
L’AI sta imponendo una conversazione più sfumata.
Quando i processori diventano abbastanza veloci, la sfida più grande smette di essere la capacità di eseguire operazioni e diventa la capacità di mantenere quei processori riforniti di dati utili con sufficiente continuità da evitare costosi tempi morti. Questo cambiamento sottile sta ora influenzando quasi ogni grande decisione architetturale dentro le moderne infrastrutture AI.
La parte interessante è che la soluzione non consiste più semplicemente nel costruire dispositivi di storage più veloci o pool di memoria più grandi in modo isolato. Al contrario, il settore si sta concentrando sempre di più su dove vivono i dati all’interno del sistema, su quanto spesso si muovono e su quanto intelligentemente l’architettura possa ridurre il trasporto non necessario prima ancora che le risorse di calcolo entrino in gioco.
Ecco perché la prossimità è diventata un tema così ricorrente in ogni articolo di questa serie. La HBM ha spostato la memoria fisicamente più vicino alla GPU. La Storage Class Memory ha ridotto il divario tra memoria e storage. La High Bandwidth Flash ha cercato di far partecipare la NAND in modo più attivo alla gerarchia della memoria. I sistemi di storage distribuito e le architetture di elaborazione vicino ai dati stanno ora cercando di ridurre quanto movimento avviene nell’infrastruttura stessa.
Tutti questi sviluppi rispondono alla stessa consapevolezza.
Su scala AI, spostare i dati in modo efficiente sta diventando quasi importante quanto elaborarli una volta che arrivano.
E questo potrebbe finire per diventare uno dei cambiamenti architetturali più importanti dell’intera era dell’AI.
Serie sull’infrastruttura di memoria per AI
Questo articolo fa parte della nostra serie in corso su come l’infrastruttura AI stia rimodellando il rapporto tra memoria, storage e calcolo. Se ti stai unendo alla discussione da qui, gli articoli precedenti forniscono le basi per capire perché questo cambiamento sta avvenendo.
Articolo uno:
La NAND non sta scomparendo, ma i server AI oggi dipendono da più del semplice flash
Articolo due:
Cos’è la High Bandwidth Memory (HBM) e perché l’AI dipende da essa
Articolo tre:
Storage Class Memory spiegata: il livello mancante tra DRAM e NAND
Articolo quattro:
High Bandwidth Flash: la NAND può finalmente comportarsi come memoria?
Articolo cinque:
Perché la DRAM da sola non riesce più a stare al passo con l’AI
Articolo sei:
Perché gli hard disk restano ancora fondamentali per l’infrastruttura AI
Articolo sette:
Perché l’AI sta spostando il calcolo più vicino allo storage
Nota editoriale: Questo articolo fa parte della serie in corso sull’infrastruttura AI e sull’architettura della memoria pubblicata da GetUSB.info. L’articolo è stato ricercato e scritto con supporto editoriale assistito dall’AI per struttura e leggibilità, poi rivisto e perfezionato dal team editoriale di GetUSB per accuratezza tecnica, continuità e chiarezza.
Informazioni sull’autore
Questo articolo è stato sviluppato sotto la direzione di Matt LeBoff, collaboratore di lunga data di GetUSB.info con oltre due decenni di esperienza nella tecnologia USB, nel comportamento della memoria flash e nei sistemi di archiviazione dati. La prospettiva presentata qui riflette conoscenza pratica del settore e analisi continua di come i sistemi reali si comportano con carichi di lavoro in evoluzione, inclusa l’infrastruttura AI.