Perché la DRAM da sola non riesce più a stare al passo con l’AI

Quando inizi a osservare da vicino come vengono davvero costruiti i sistemi di AI, c’è una conclusione molto naturale a cui le persone tendono ad arrivare e, a dire il vero, all’inizio sembra perfettamente ragionevole.
Se il NAND è troppo lento per certe parti del carico di lavoro, e perfino le architetture flash più avanzate introducono comunque abbastanza ritardo da farsi sentire, allora la risposta ovvia sembrerebbe aggiungere più DRAM. Dopotutto, la DRAM è sempre stata il livello veloce. È lì che vivono i dati attivi, risponde rapidamente e, da decenni, è la parte del sistema su cui fai affidamento quando non vuoi che il processore resti fermo ad aspettare che qualcosa arrivi.
Quindi è facile fare questa supposizione: se il problema è la velocità, allora bisogna espandere la cosa più veloce che si ha.
Questa logica regge piuttosto bene finché non entra in scena l’AI e comincia a spingere la DRAM dentro un ruolo per cui, in realtà, non è mai stata davvero progettata. Il problema non è che la DRAM sia improvvisamente diventata lenta, o obsoleta, o in qualche modo meno utile di prima. Il problema è che i carichi di lavoro AI le stanno chiedendo di fare molto di più che agire semplicemente come un veloce livello operativo tra compute e storage.
Per il quadro più ampio dietro questo cambiamento, questo articolo si collega direttamente al pezzo pillar principale qui: Il NAND non sta scomparendo, ma i server AI oggi dipendono da più del semplice flash.
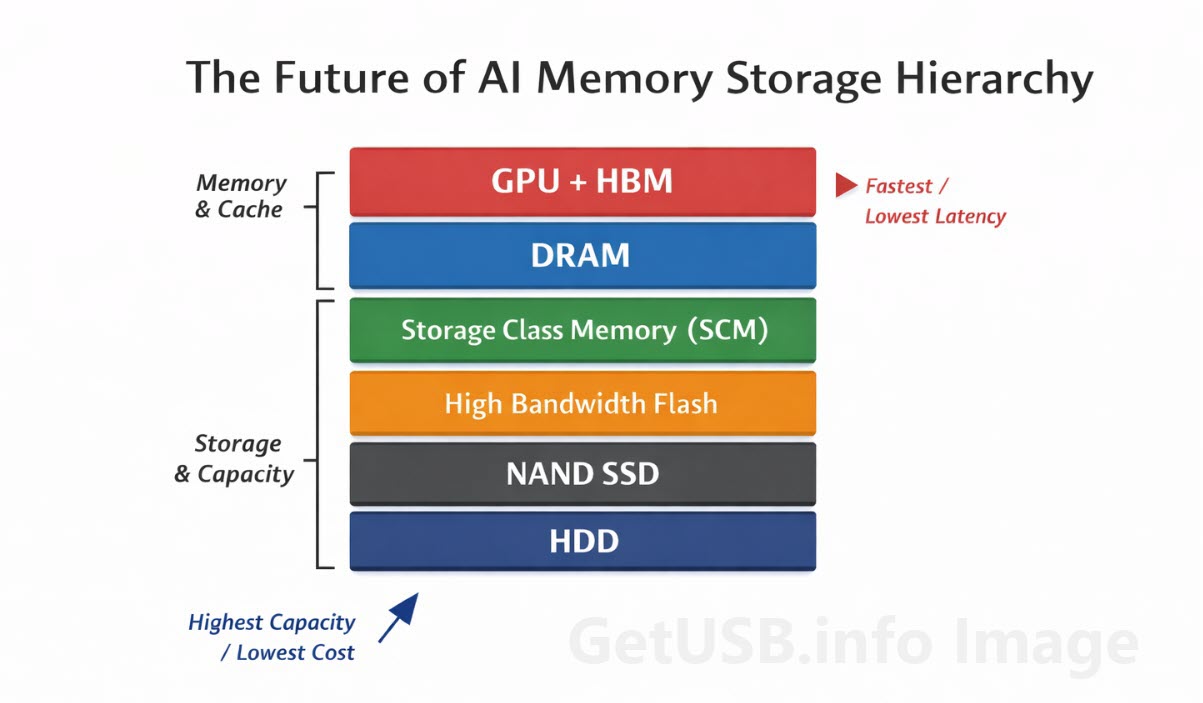
La DRAM è stata costruita per la velocità, non per sostenere l’intero sistema
La prima cosa da capire è che la DRAM è sempre stata ottimizzata per la velocità e la reattività, non per contenere enormi quantità di dati su larga scala. Nell’informatica tradizionale, questa distinzione raramente era un problema perché la maggior parte dei carichi di lavoro aveva una separazione piuttosto chiara tra dati attivi e dati archiviati. Il sistema teneva in memoria ciò di cui aveva bisogno nell’immediato, richiamava il resto dallo storage quando serviva e il passaggio tra i due livelli era di solito abbastanza buono da far sì che nessuno ci pensasse troppo.
L’AI cambia questo equilibrio in modo piuttosto drastico. Invece di lavorare su blocchi contenuti di dati attivi e poi passare oltre, i modelli AI tendono a rivisitare grandi dataset più volte, a spostare informazioni in parallelo e a mantenere una porzione molto più ampia del working set a portata del livello di compute per periodi di tempo molto più lunghi. Questo significa che alla DRAM non viene più chiesto semplicemente di contenere il compito corrente. Le viene chiesto di aiutare a trattenere un enorme corpo di dati, in costante movimento, che il sistema vuole avere vicino praticamente in ogni momento.
È un lavoro completamente diverso.
Ed è anche il motivo per cui le tecnologie sopra e attorno alla DRAM sono diventate più importanti. Nel precedente articolo su che cos’è la High Bandwidth Memory e perché l’AI dipende da essa, il focus era spostare una quantità più piccola di dati critici estremamente vicino al processore in modo che la GPU resti sempre alimentata. Quell’articolo sottolinea che la vicinanza conta, ma rivela anche in modo silenzioso il problema successivo, perché una volta che il working set cresce oltre quel livello immediato, il sistema deve comunque decidere dove debba vivere tutto il resto.
Il primo muro è il costo, e si presenta molto in fretta
Uno dei motivi per cui alle persone piace l’idea del “basta aggiungere più DRAM” è che suona pulita e diretta. Nella pratica, però, diventa molto costosa molto rapidamente. La DRAM semplicemente non ha lo stesso prezzo del NAND e, quando inizi a scalare sistemi nel territorio dell’AI, non stai più parlando di aggiungere un po’ di memoria extra a un server. Stai parlando di centinaia di gigabyte, a volte molti di più, distribuiti tra numerosi nodi, rack e cluster.
A quel punto, la DRAM smette di sembrare un upgrade prestazionale e comincia ad apparire come un peso infrastrutturale. La curva dei costi non sale in modo graduale. Sale abbastanza velocemente da far sì che l’idea di usare la DRAM per risolvere ogni problema di località dei dati inizi a sgretolarsi sotto il proprio stesso peso economico.
Questo è uno dei motivi per cui lo stack della memoria sta diventando più profondo invece che più semplice. Il settore non si sta allontanando dalla DRAM perché ha smesso di essere preziosa. Si sta allontanando dall’idea che la DRAM, da sola, possa essere la risposta a ogni problema sensibile alla latenza su scala AI.
Il secondo muro è l’energia, e questo problema non dorme mai
Anche se il costo fosse più facile da giustificare, la DRAM si scontra comunque con un altro problema che diventa impossibile da ignorare una volta che i sistemi crescono abbastanza, ed è l’energia. La DRAM deve essere costantemente alimentata per mantenere il proprio stato. Fa semplicemente parte della tecnologia. Quindi, più ne aggiungi, più energia il sistema consuma semplicemente per tenere quei dati lì, pronti all’uso.
In ambienti più piccoli, questo sovraccarico può sembrare accettabile. In sistemi AI densi che funzionano in modo continuo, comincia a diventare un serio problema operativo. Più DRAM significa più assorbimento di potenza, più calore, più raffreddamento e più pressione progettuale sull’intera piattaforma. Improvvisamente la decisione non riguarda più solo la capacità di memoria. Riguarda i limiti termici, l’efficienza del data center e il fatto che l’infrastruttura di supporto possa o meno assorbire il costo di mantenere viva, ventiquattro ore su ventiquattro, una tale quantità di memoria attiva.
È anche qui che il ruolo dei livelli intermedi inizia ad avere più senso. Nel precedente articolo su Storage Class Memory, il livello mancante tra DRAM e NAND, l’idea non era sostituire la DRAM, ma alleggerire parte della pressione su di essa introducendo un livello che mantenga più dati vicini al compute senza costringere tutto a finire nel tier più costoso e più affamato di energia.
Poi c’è la realtà fisica della vicinanza
C’è un altro motivo per cui la DRAM non scala all’infinito nei sistemi AI, e ha meno a che fare con il budget e più con la fisica. La DRAM offre valore anche perché si trova relativamente vicina al processore. Più la memoria è vicina al compute, più la latenza tende a essere bassa e più l’intero sistema appare reattivo. Ma la vicinanza non è qualcosa che puoi espandere per sempre senza conseguenze.
Esistono limiti fisici alla quantità di memoria che può essere collocata vicino a una CPU o a una GPU prima che complessità del layout, lunghezza delle tracce, integrità del segnale e vincoli di packaging inizino a giocare contro di te. È esattamente per questo che è comparso il packaging di memoria avanzato. L’HBM esiste perché il posizionamento tradizionale della DRAM può spingersi solo fino a un certo punto, e una volta che il lato compute diventa abbastanza veloce, quelle distanze e quei percorsi iniziano a contare molto di più di quanto contassero un tempo.
Ma l’HBM non è nemmeno una risposta completa sul fronte della capacità. Offre una larghezza di banda incredibile, ma non un volume illimitato. Così il sistema finisce per vivere in un costante equilibrio tra ciò che può essere collocato molto vicino e ciò che deve stare più lontano. I carichi di lavoro AI mettono sotto pressione questo equilibrio molto più duramente di quanto abbiano mai fatto i sistemi convenzionali.
L’AI rende costosi anche i piccoli ritardi
Una delle cose più interessanti dell’infrastruttura AI è che mette in evidenza inefficienze che i carichi di lavoro più vecchi riuscivano per lo più a nascondere. In un sistema più tradizionale, un leggero ritardo nell’accesso ai dati potrebbe non significare molto. Il processore aspetta un po’, il compito finisce un po’ più tardi e l’utente non se ne accorge nemmeno. I sistemi AI sono molto meno indulgenti perché operano con tantissimo parallelismo e con così tanto denaro legato al livello di compute.
Se una GPU non riceve i dati nel momento in cui ne ha bisogno, non è solo un fastidio tecnico. È tempo morto costoso. Moltiplica questo problema per molti acceleratori che lavorano in parallelo e anche ritardi molto piccoli iniziano a tradursi in perdite reali di utilizzo.
Questo cambia l’obiettivo. L’obiettivo non è semplicemente avere memoria veloce. L’obiettivo è mantenere una consegna dei dati sufficientemente costante, su una scala abbastanza grande da tenere occupate tutto il tempo le parti più costose del sistema. È un requisito molto più duro, ed è proprio per questo che la sola DRAM comincia a sembrare insufficiente una volta che l’infrastruttura AI supera una certa soglia.

L’analogia del magazzino funziona ancora – semplicemente diventa più grande
Se continuiamo a usare la stessa analogia del magazzino dei precedenti articoli, la DRAM è ancora il punto di carico. È il luogo in cui avviene il lavoro attivo, dove gli articoli vengono aperti, smistati e portati all’uso immediato. Per anni, questo modello ha funzionato bene perché la quantità di attività al punto di carico era gestibile e il sistema non richiedeva che tutto fosse preparato lì nello stesso momento.
L’AI cambia la scala dell’operazione. Ora il punto di carico deve sostenere un flusso quasi continuo di materiale, con molta più attività in parallelo e molta meno tolleranza ai ritardi. A un certo punto, anche il miglior punto di carico non può continuare a espandersi semplicemente all’infinito. C’è solo un certo spazio disponibile, solo un certo numero di movimenti paralleli che possono avvenire in modo efficiente, e solo una certa quantità di inventario che puoi tenere direttamente nel punto d’uso prima che il layout stesso diventi parte del problema.
Quindi la risposta non è rendere il punto di carico infinitamente più grande. La risposta è riprogettare il flusso di lavoro attorno a esso.
È qui che il resto della gerarchia della memoria inizia a guadagnarsi il proprio posto. L’HBM mantiene i dati più sensibili al tempo proprio accanto al processore. La Storage Class Memory aiuta a rendere più fluida la transizione tra memoria attiva e storage più lento. E nel più recente articolo su perché i moderni sistemi di intelligenza artificiale consumano così tanta memoria, l’attenzione si è spostata su come anche il lato storage venga riprogettato per partecipare in modo più intelligente all’alimentazione del sistema.
Nessuno di questi livelli esiste perché la DRAM ha fallito. Esistono perché l’AI è andata oltre l’idea che un singolo livello veloce potesse sostenere da solo l’intero carico di lavoro.
Cosa significa davvero tutto questo per lo stack di memoria dell’AI
Il vero punto qui non è che la DRAM stia scomparendo, perché chiaramente non è così. La DRAM rimane una delle parti più importanti dell’intero stack. Quello che sta cambiando è il suo ruolo. Invece di essere il luogo in cui dovrebbe vivere tutto ciò che è attivo, la DRAM sta diventando il luogo in cui vivono i dati più urgenti e più sensibili al tempo, mentre altri livelli gestiscono il crescente peso di scala, costo e capacità.
È un cambiamento sottile, ma importante. Significa che l’infrastruttura AI si sta allontanando dalla vecchia idea di un semplice modello a due livelli – memoria da una parte, storage dall’altra – per andare verso qualcosa di molto più sfumato, in cui a tecnologie diverse viene chiesto di gestire la parte del carico di lavoro per cui sono più adatte.
In parole semplici, la DRAM è ancora essenziale, ma non basta più da sola. L’AI ha cambiato la dimensione del working set, la velocità del compute, il costo del ritardo e l’economia del mantenere tutto vicino. Quando tutto questo cambia nello stesso momento, anche la gerarchia della memoria deve cambiare con esso.
Dove porta tutto questo, nel prossimo passo
Una volta accettato che la DRAM non può estendersi abbastanza da contenere tutto ciò che l’AI vuole avere vicino al compute, la domanda successiva diventa piuttosto ovvia. Dove vivono davvero tutti quegli altri dati, soprattutto quando la quantità di informazioni coinvolte è troppo grande per giustificare il fatto di tenerla in memoria?
È qui che la conversazione cambia di nuovo, e una tecnologia che molti danno ormai per superata torna a contare in modo sorprendentemente importante. Perché, mentre la DRAM fatica con la scala e il flash continua a portarsi dietro i propri compromessi in termini di costo e latenza, i dischi rigidi continuano a offrire qualcosa che il resto dello stack non può sostituire facilmente: capacità pratica su volumi enormi.
Ed è esattamente per questo che la prossima parte di questa serie dovrà guardare al motivo per cui i dischi rigidi restano ancora fondamentali per l’infrastruttura AI.
Informazioni sull’autore
Questo articolo è stato sviluppato sotto la direzione di Greg Morris, collaboratore di lunga data di GetUSB.info con oltre due decenni di esperienza nella tecnologia USB, nel comportamento della memoria flash e nei sistemi di archiviazione dati. La prospettiva presentata qui riflette esperienza pratica di settore e un’analisi continua di come i sistemi reali si comportano sotto carichi di lavoro in evoluzione, inclusa l’infrastruttura AI.
Come è stato creato questo articolo
I concetti, la struttura e la direzione tecnica di questo articolo sono stati elaborati e revisionati da un esperto umano del settore. Gli strumenti di AI sono stati utilizzati per assistere con ritmo, fluidità e leggibilità, aiutando a organizzare idee complesse in una narrazione più naturale senza alterare l’accuratezza tecnica di fondo né l’intento originale.
Informazioni sulle immagini
Le immagini utilizzate in questo articolo sono state create appositamente per illustrare concetti difficili da catturare con la fotografia stock tradizionale, come colli di bottiglia nel flusso dei dati, comportamento della gerarchia della memoria e inefficienze a livello di sistema. Le immagini sono pensate per rafforzare le spiegazioni tecniche e migliorare la chiarezza per i lettori.