
Il NAND non sta scomparendo, ma i server AI oggi dipendono da più del semplice flash
Da oltre due decenni, GetUSB osserva come i dati si muovono realmente, non solo come vengono raccontati dal marketing. In questo periodo abbiamo visto lo storage evolversi attraverso diversi cicli, dal declino dei dischi meccanici alla crescita della memoria flash, fino ad arrivare più recentemente a sistemi in cui lo storage non è più solo un componente passivo, ma parte integrante dell’infrastruttura stessa.
Quello che sta accadendo ora con l’infrastruttura AI sembra un altro di quei momenti di transizione, ma guidato da un tipo di pressione diverso.
La memoria NAND non sta scomparendo, e su questo non c’è davvero discussione. Rimane la base dello storage moderno e svolge quel ruolo in modo estremamente efficace. Allo stesso tempo, la domanda di NAND è aumentata rapidamente, in gran parte a causa dei carichi di lavoro AI che richiedono dataset enormi e accesso continuo a tali dati. Questa domanda sta iniziando a scontrarsi con l’offerta in modi sempre più difficili da ignorare, che si tratti di pressione sui prezzi, allocazioni più restrittive o semplicemente tempi di consegna più lunghi per implementazioni su larga scala.
Quando questo tipo di squilibrio inizia a emergere, l’industria non resta ferma ad aspettare che la situazione si normalizzi. Inizia a cercare altri modi per risolvere il problema, ed è qui che le cose cominciano a cambiare.
L’assunzione che fanno tutti
Se lo guardi dall’esterno, la logica sembra ancora piuttosto sensata. I modelli AI stanno diventando più grandi, i dataset continuano a crescere e viene costruita sempre più infrastruttura per supportarli, quindi la risposta naturale è aggiungere più storage. Più SSD, più capacità, più flash nel rack, e il sistema dovrebbe riuscire a tenere il passo.
Questo approccio ha funzionato per molto tempo e in molti ambienti funziona ancora. Il problema è che si basa sull’idea che lo storage si comporti allo stesso modo nei carichi AI come nei carichi più tradizionali, ed è proprio qui che le cose iniziano a divergere.
Presuppone anche che il NAND continui a essere disponibile nelle quantità necessarie e a prezzi prevedibili, cosa che sta diventando sempre meno certa man mano che la domanda accelera.
Dove il NAND inizia a mostrare i suoi limiti
La memoria NAND è eccezionalmente efficace in ciò per cui è stata progettata. Offre storage denso, affidabile e relativamente veloce, e per il computing general-purpose ha risolto una lunga serie di problemi che esistevano con le tecnologie precedenti. Ancora oggi, per la maggior parte dei carichi di lavoro, si comporta esattamente come previsto.
I carichi AI, però, chiedono qualcosa di leggermente diverso, e questa differenza conta più di quanto possa sembrare inizialmente.
Invece di limitarsi a memorizzare i dati e recuperarli quando necessario, questi sistemi richiedono un flusso costante e continuo di dati verso risorse di calcolo altamente parallele, spesso a velocità difficili da mantenere in modo costante con le architetture di storage tradizionali. Gli SSD ad alte prestazioni possono gestire picchi di attività e code di transazioni molto lunghe, ma alimentare in tempo reale migliaia di core GPU è una richiesta completamente diversa.
Allo stesso tempo, il supporto sottostante – il NAND stesso – sta diventando più costoso e, in alcuni casi, più difficile da reperire in grandi volumi. L’industria si trova quindi ad affrontare due pressioni contemporaneamente: la necessità di una maggiore e più costante velocità di trasferimento dei dati e la realtà che il principale mezzo utilizzato per fornire questi dati è sotto pressione sia in termini di disponibilità che di costo.
Questa combinazione è ciò che sta guidando il cambiamento attuale. Non perché il NAND abbia smesso di funzionare, ma perché affidarsi esclusivamente ad esso non è più sufficiente per stare al passo con ciò che i sistemi AI stanno cercando di fare.
L’industria non ha sostituito il NAND – ci ha costruito intorno
Quello che sta iniziando a succedere nell’infrastruttura AI non è una sostituzione netta del NAND, e non è nemmeno un cambiamento improvviso in cui la flash scompare dall’equazione. Anzi, il NAND è ancora molto al centro di questi sistemi. La differenza è che non ci si aspetta più che sostenga l’intero carico da solo.
Al contrario, l’industria sta costruendo livelli aggiuntivi attorno ad esso, ciascuno progettato per gestire una parte specifica del carico che il NAND non era realmente pensato per affrontare da solo. In pratica, questo significa ripensare il modo in cui i dati si muovono all’interno di un sistema, dove risiedono nelle diverse fasi e quanto rapidamente devono essere accessibili in base a ciò che sta facendo il lato compute.
È qui che il concetto di memory stack inizia a emergere più spesso. Non come termine di marketing, ma come modo pratico per descrivere ciò che viene realmente implementato. Invece di trattare storage e memoria come due categorie separate, i sistemi AI stanno iniziando a sfumare questa distinzione, creando più livelli che si comportano in modo diverso in base a velocità, costo e vicinanza al processore.
Il NAND continua a svolgere un ruolo critico in questo stack, soprattutto per la capacità, ma ora si affianca ad altre tecnologie progettate per gestire quelle parti del carico in cui latenza e larghezza di banda contano più del semplice volume di storage.
Cosa viene costruito attorno al NAND
Una volta che si osserva il sistema in questo modo, i cambiamenti iniziano ad avere più senso. Invece di forzare il NAND a fare tutto, l’industria introduce altri livelli, ciascuno dei quali risolve un problema specifico. Alcuni di questi sono già in produzione, altri sono ancora in evoluzione, ma insieme formano la struttura su cui i moderni server AI stanno iniziando a fare affidamento.
Nei prossimi articoli entreremo più nel dettaglio su ciascuno di questi livelli, perché ognuno merita più spazio di quanto un articolo pillar possa ragionevolmente offrire. Per ora, l’obiettivo è mostrare come i vari elementi si incastrano tra loro, così che questo articolo possa funzionare autonomamente e allo stesso tempo preparare il terreno per gli approfondimenti successivi.
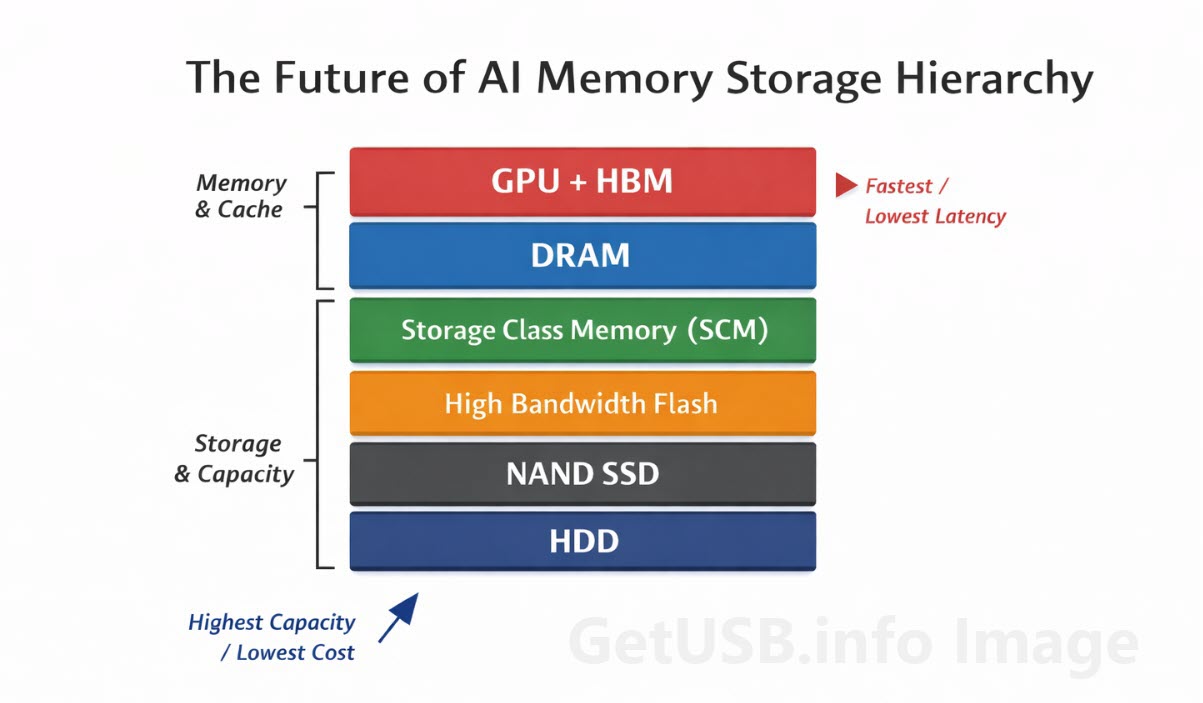
High Bandwidth Memory (HBM)
Al vertice dello stack, il più vicino possibile alla GPU, si trova la High Bandwidth Memory, o HBM. Si tratta di un tipo di DRAM impilata che si trova fisicamente vicino al processore ed è progettata per fornire una velocità di trasferimento dati estremamente elevata con una latenza molto bassa. Non è un dispositivo di storage nel senso tradizionale, ma una forma specializzata di memoria costruita specificamente per alimentare le GPU moderne alla velocità richiesta.
L’HBM non riguarda la capacità. Riguarda il mantenere la GPU costantemente occupata, che nei sistemi AI è spesso il componente più costoso del rack. Se il processore deve aspettare i dati, tutto ciò che sta dietro diventa meno efficiente. L’HBM risolve questo problema dando priorità alla larghezza di banda e alla vicinanza rispetto alla dimensione.
Se lo immagini in termini di magazzino, l’HBM è come avere il pallet successivo già pronto al dock di carico, con l’imballaggio rimosso e pronto per essere movimentato. Non stai aumentando la quantità totale di inventario nel magazzino, ma stai assicurando che il carrello elevatore non debba mai fermarsi ad aspettare il prossimo carico.
Per un approfondimento su come l’HBM si confronta con le alternative emergenti, abbiamo trattato l’argomento qui: HBM vs HBF: Why the Memory Hierarchy is Being Stretched
Storage Class Memory (SCM)
Subito sotto si trova una categoria che, fino a pochi anni fa, non esisteva davvero in modo pratico: storage che si comporta più come memoria.
La Storage Class Memory, o SCM, colma il divario tra DRAM e NAND. Non ha la velocità della memoria pura e non ha la densità della flash, ma offre un equilibrio che la rende utile per carichi di lavoro che richiedono un accesso più rapido rispetto a quello che il NAND può fornire senza sostenere il costo completo della DRAM su larga scala.
Negli ambienti AI, questo livello intermedio aiuta ad assorbire parte della pressione che altrimenti ricadrebbe direttamente sul NAND, soprattutto quando si gestiscono grandi dataset di lavoro che non rientrano perfettamente nella memoria tradizionale.
L’analogia più semplice è quella del magazzino: la SCM è l’area di staging tra gli scaffali principali e il dock di carico. Il magazzino può contenere tutto, ma è troppo lento dover tornare continuamente tra le corsie ogni volta che serve una nuova scatola. Il dock è veloce, ma lo spazio è limitato. La SCM è l’area intermedia dove vengono preparate le spedizioni più probabili, così il flusso continua senza dover trasformare il dock nell’intero magazzino.
High Bandwidth Flash
Qui le cose diventano particolarmente interessanti, perché invece di introdurre un tipo completamente nuovo di memoria, l’industria sta anche cercando modi per spingere il NAND stesso in un nuovo territorio.
La High Bandwidth Flash è un tentativo di far comportare la flash meno come uno storage tradizionale e più come un’estensione della memoria. L’obiettivo non è sostituire il NAND, ma cambiare il modo in cui viene accesso e integrato, in modo da fornire dati in modo più efficiente ai livelli superiori.
In un certo senso, è il NAND che si adatta al nuovo contesto invece di essere sostituito, cosa che si allinea con ciò che abbiamo visto nelle transizioni precedenti. Le tecnologie raramente scompaiono dall’oggi al domani; evolvono per rimanere rilevanti.
DRAM e i suoi limiti
La DRAM continua a svolgere un ruolo centrale in tutto questo e non sta andando da nessuna parte. Rimane la memoria di lavoro principale per la maggior parte dei sistemi, inclusi i server AI, e gestisce una grande parte dei dati attivi che devono essere accessibili rapidamente.
Allo stesso tempo, scalare la DRAM all’infinito non è pratico. Costi, consumo energetico e vincoli fisici entrano tutti in gioco, soprattutto man mano che i sistemi crescono. Di conseguenza, la sola DRAM non può assorbire tutta la domanda aggiuntiva generata dai carichi AI, ed è proprio per questo che vengono introdotti questi altri livelli.
In termini di magazzino, la DRAM è come il pavimento del dock di carico. È lì che avviene il lavoro attivo, dove le scatole vengono aperte, ordinate e spostate alla fase successiva il più rapidamente possibile. Il problema è che lo spazio del dock è limitato: oltre un certo punto, costi, energia e layout smettono di avere senso. A quel punto servono comunque aree di staging vicine e storage più profondo alle spalle, perché fare tutto sul dock diventa inefficiente e costoso.
Il ritorno silenzioso degli hard disk
Nonostante tutta l’attenzione su memoria ad alta velocità e flash, i dischi rigidi tradizionali fanno ancora parte del quadro, soprattutto nella parte bassa dello stack dove il costo per terabyte conta più della velocità.
I sistemi AI generano e consumano enormi quantità di dati, e non tutto deve risiedere su storage ad alte prestazioni. Dataset di training, archivi e informazioni meno frequentemente accessibili devono comunque essere conservati da qualche parte, e per questo gli hard disk restano una delle opzioni più economiche disponibili.
Non competono con NAND o memoria in termini di prestazioni, ma riducono la pressione complessiva su questi livelli occupandosi dello storage di massa.
Avvicinare il calcolo allo storage
Un altro cambiamento che sta guadagnando attenzione è l’idea di ridurre la distanza che i dati devono percorrere. Invece di spostare continuamente grandi quantità di dati avanti e indietro tra storage e compute, alcune architetture stanno iniziando a portare l’elaborazione più vicino a dove i dati risiedono.
Questo approccio non elimina la necessità di memoria o storage veloci, ma cambia l’equilibrio. Gestendo alcune operazioni più vicino ai dati, i sistemi possono ridurre i colli di bottiglia e migliorare l’efficienza complessiva senza affidarsi esclusivamente a supporti più veloci.
Il ruolo del contesto AI (KV cache)
Uno dei fattori meno evidenti che guidano tutto questo è la quantità di dati temporanei che i modelli AI generano durante l’esecuzione. Questo viene spesso chiamato contesto o KV cache e rappresenta lo stato operativo del modello mentre elabora input e genera output.
Questi dati non si adattano sempre perfettamente alla memoria tradizionale, soprattutto su larga scala, ed è per questo che i sistemi iniziano a trattare lo storage come un’estensione della memoria piuttosto che come un livello completamente separato. È un altro esempio di come i confini tra queste categorie stiano diventando sempre meno netti.
Anche qui funziona l’analogia del magazzino. La KV cache è come il registro operativo e la lista di picking attiva per tutto ciò che viene attualmente preparato, ordinato e spedito. Non è l’inventario completo e non è storage a lungo termine, ma se questo stato operativo diventa troppo grande o difficile da consultare, l’intera operazione rallenta perché nessuno sa cosa è stato appena prelevato, cosa viene dopo o a che punto è l’ordine corrente.
Il nuovo stack di memoria AI
Se fai un passo indietro e osservi il sistema nel suo insieme, inizia a somigliare più a una struttura a strati che a una semplice gerarchia.
In cima trovi la GPU con HBM, che gestisce operazioni immediate ad alta velocità. Subito dietro c’è la DRAM, che gestisce carichi attivi che richiedono accesso rapido ma non devono essere direttamente sul processore. Più in basso, livelli emergenti come SCM e high-bandwidth flash colmano il divario tra memoria e storage, offrendo capacità aggiuntiva senza sacrificare troppo le prestazioni.
Ancora più in basso, il NAND tradizionale continua a gestire lo storage su larga scala, mentre gli hard disk assumono il ruolo di archiviazione a lungo termine e a basso costo.
Se immagini tutto questo come un magazzino, la struttura diventa più chiara. L’HBM è il pallet pronto al dock, la DRAM è il pavimento dove avviene il lavoro, la SCM è l’area di staging subito dietro, il NAND sono gli scaffali principali e gli hard disk sono lo storage profondo sul retro dove costi e capacità contano più della velocità. Il sistema funziona perché ogni livello ha un ruolo e perché nessuno si aspetta che il fondo del magazzino faccia il lavoro del dock.
Ogni livello ha uno scopo, e insieme formano un sistema più adatto alle esigenze dell’AI rispetto a qualsiasi singola tecnologia presa da sola.
Cosa significa per il futuro
Il punto qui non è che il NAND venga sostituito o che una nuova tecnologia prenda il suo posto. Quello che sta accadendo è più graduale e, in molti sensi, più interessante.
L’industria sta riconoscendo che nessun singolo livello può gestire tutto, soprattutto sotto la pressione dell’AI. Invece di spingere una tecnologia oltre i suoi limiti, sta costruendo un sistema in cui più livelli lavorano insieme, ciascuno ottimizzato per un ruolo specifico.
Questo cambiamento modifica il modo in cui pensiamo allo storage. Non si tratta più solo di capacità o velocità pura, ma di come i dati si muovono attraverso il sistema e di quanto efficientemente ogni livello supporta quello sopra di esso.
E mentre queste architetture continuano a evolversi, il NAND rimane una parte fondamentale del quadro – semplicemente non è più l’unica.
Tags: HBM, Infrastruttura AI, memory stack AI, NAND flash, storage class memory
Trackback dal tuo sito.